Imbalanced datasets are a common problem in classification tasks in machine learning. Take credit card fraud prediction as a simple example: the target values are either fraud (1) or not fraud (0), but the number of fraud (1) could only be less than one percent of the whole dataset.
In this case, any model could "predict" all customers will not default and easily get 99% accuracy. This is due to most algorithms are designed to reduce error.
There are several commonly used approaches to deal with such problem. Namely two groups: resampling and ensembling.
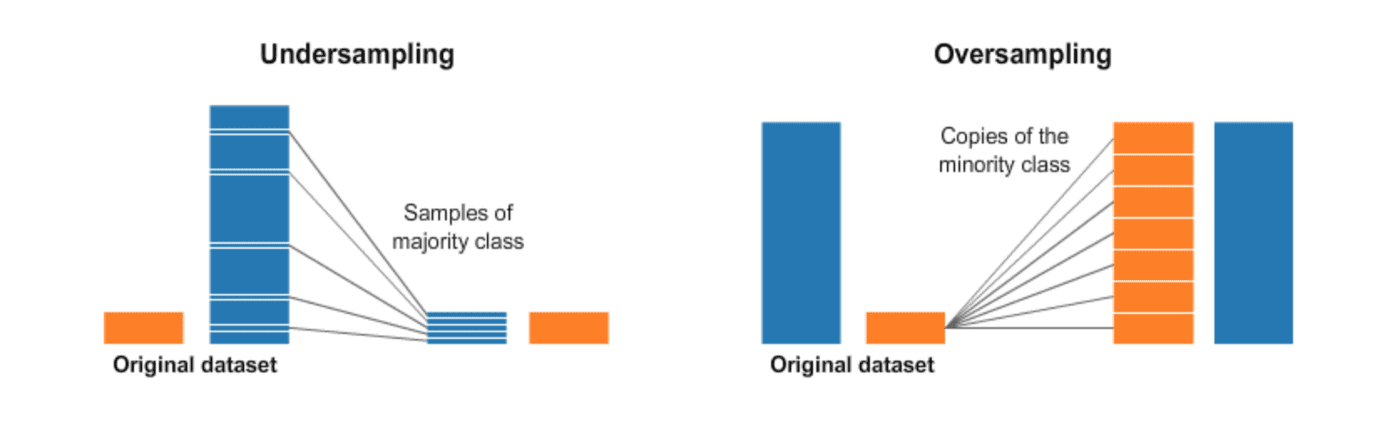
1. Undersampling / Downsampling
Undersampling is the process where you randomly delete some of the observations from the majority class in order to match the numbers with the minority class.
Undersampling would be helpful if the minority class contains decent amount of data. Otherwise, undersampling would make the dataset quit small. Further, the data we are dropping could be important.
2. Oversampling / Upsampling
Oversampling is the process that reproduce data for the minority class to match the number of observations in the majority class. Oversampling can be a good choice when the minority class contains few observations.
Important: Always split into test and train sets BEFORE trying oversampling techniques! Oversampling before splitting the data can allow the exact same observations to be present in both the test and train sets. This can cause overfitting and poor generalization to the test data.
There are several ways to generate data for the minority class. Following is a simple example to oversample the minority class:
SMOTE
There is a widely used oversampling technique called SMOTE (Synthetic Minority Over-sampling Technique). In simple terms, it looks at the feature space for the minority class data points and considers its k-nearest neighbours.
Again, it’s important to generate the new samples only in the training set to ensure our model generalizes well to unseen data.
3. sklearn's Approach
The Scikit-Learn package provides a integrated way to tackle this problem by setting up the class_weight='balance'. This is supported by several classifiers like decision tree.