From K-means we know that:
K-means forces clusters to be spherical In K-means clustering every point can only belong to one cluster But sometimes it might be desirable to have elliptical clusters than spherical clusters. And what if there is a data point right in the center of two clusters?
Gaußian Mixture Mode With a random variable X X X
p ( x ) = ∑ k = 1 K π k N ( X ∣ μ k , Σ k ) p(x)=\sum_{k=1}^{K} \pi_{k} \mathcal{N}\left(X | \mu_{k}, \Sigma_{k}\right) p ( x ) = k = 1 ∑ K π k N ( X ∣ μ k , Σ k ) where N ( X ∣ μ k , Σ k ) \mathcal{N}\left(X | \mu_{k}, \Sigma_{k}\right) N ( X ∣ μ k , Σ k ) k t h k^{th} k t h
Generalized Form Then we can generate a generalized form:
p ( X ∣ M , Σ , π ) = ∏ i = 1 s ∑ k = 1 K π k N ( x i ∣ μ k , Σ k ) p(X | M, \Sigma, \pi)=\prod_{i=1}^{s} \sum_{k=1}^{K} \pi_{k} \mathcal{N}\left(x_{i} | \mu_{k}, \Sigma_{k}\right) p ( X ∣ M , Σ , π ) = i = 1 ∏ s k = 1 ∑ K π k N ( x i ∣ μ k , Σ k ) for N ( x i ∣ μ k , Σ k ) = 1 ( 2 π ) n det ( Σ k ) e − 1 2 ⟨ Σ k − 1 ( x i − μ k ) , x i − μ k ⟩ \text{for} \quad \mathcal{N}\left(x_{i} | \mu_{k}, \Sigma_{k}\right)=\frac{1}{\sqrt{(2 \pi)^{n} \operatorname{det}\left(\Sigma_{k}\right)}} e^{-\frac{1}{2}\left\langle\Sigma_{k}^{-1}\left(x_{i}-\mu_{k}\right), x_{i}-\mu_{k}\right\rangle} for N ( x i ∣ μ k , Σ k ) = ( 2 π ) n det ( Σ k ) 1 e − 2 1 ⟨ Σ k − 1 ( x i − μ k ) , x i − μ k ⟩ where
X = ( x 1 x 2 … x s ) ∈ R n × s input data X=\left( \begin{array}{llll}{x_{1}} & {x_{2}} & {\dots} & {x_{s}}\end{array}\right) \in \mathbb{R}^{n \times s} \quad \text { input data } X = ( x 1 x 2 … x s ) ∈ R n × s input data
M = ( μ 1 μ 2 … μ K ) ∈ R n × K prototype vectors M=\left( \begin{array}{llll}{\mu_{1}} & {\mu_{2}} & {\dots} & {\mu_{K}}\end{array}\right) \in \mathbb{R}^{n \times K} \quad \text { prototype vectors } M = ( μ 1 μ 2 … μ K ) ∈ R n × K prototype vectors
Σ = ( Σ 1 Σ 2 … Σ K ) ∈ R n × n × K covariance matrices \Sigma=\left(\Sigma_{1} \quad \Sigma_{2} \quad \ldots \quad \Sigma_{K}\right) \in \mathbb{R}^{n \times n \times K} \quad \text { covariance matrices } Σ = ( Σ 1 Σ 2 … Σ K ) ∈ R n × n × K covariance matrices
π = ( π 1 π 2 … π K ) ∈ R K × 1 mixing weights \pi=\left( \begin{array}{llll}{\pi_{1}} & {\pi_{2}} & {\dots} & {\pi_{K}}\end{array}\right) \in \mathbb{R}^{K \times 1} \quad \text { mixing weights} π = ( π 1 π 2 … π K ) ∈ R K × 1 mixing weights and π k ≥ 0 for all k ∈ { 1 , … , K } as well as ∑ k = 1 K π k = 1 \text { and } \quad \pi_{k} \geq 0 \quad \text { for all } \quad k \in\{1, \ldots, K\} \quad \text { as well as } \sum_{k=1}^{K} \pi_{k}=1 and π k ≥ 0 for all k ∈ { 1 , … , K } as well as ∑ k = 1 K π k = 1
Now the goal for the algorithm is: given X , determine the parameters M, Σ and π (for example by maximizing the likelihood)
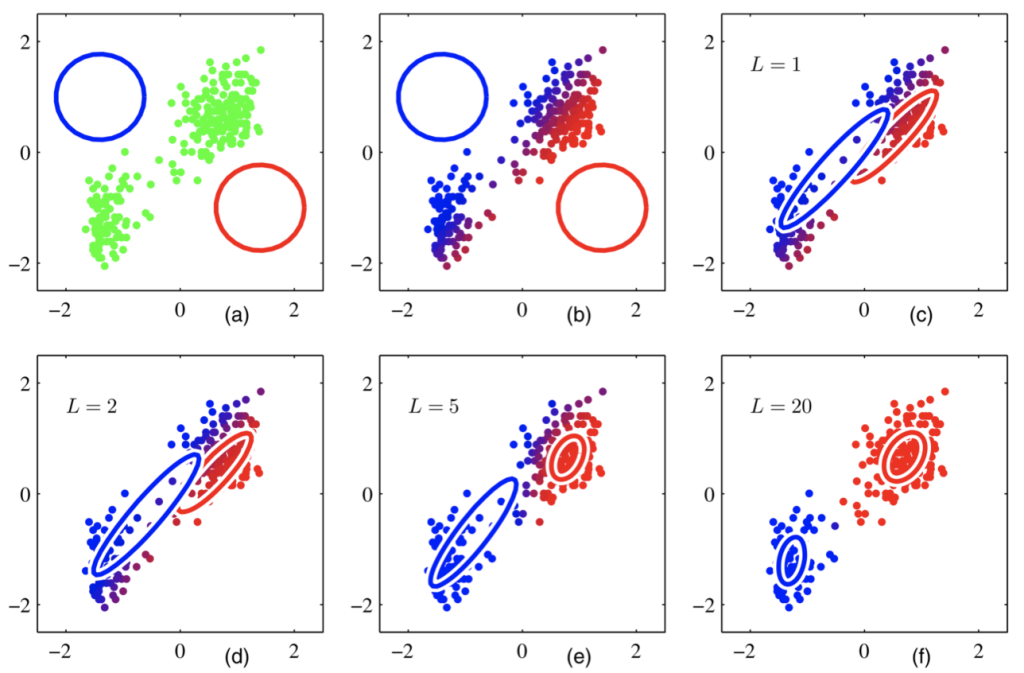
Model Iteration Illustration